超初心者向け!! RNA-seq解析シリーズの記事になります。
今回は、解析に使うデータを公共データベースからダウンロードしていきたいと思います。
NGS公共データベースからのRNA-seqデータ取得
DDBJ
では、早速公共データベースよりRNA-seqデータをダウンロードしていきます。
NGSのデータベースはDDBJやNCBI、EBIがありますが、
貯蔵されているデータはそれらの間で定期的に同期されているので、
ほぼ同じと考えて大丈夫です。
今回は_DDBJ_を使いたいと思います。
今年のノーベル賞がHIF1でしたので、
RNA-seq HIF1a mutantをキーワードに検索してみましょう。
ダウンロードファイルの検索
解析に使うデータを公共データベースより検索します。
今回は、「RNA-seq HIF1a mutant」で探してみます。
まずは、以下のリンクよりDDBJサイトを開きます。
ブラウザはChromeを激しく推奨します。
Safariだと途中でFTPが見れなくなる可能性大!!
DDBJのサイトはこちら
外部リンクhttps://www.ddbj.nig.ac.jp/dra/index.html ↗https://www.ddbj.nig.ac.jp/dra/index.html
1. DDBJのホームページを開いて、Searchをクリック
KeywordにRNA-seq HIF1a mutantといれて、DatabaseとTypeを選択。
検索画面では Keyword のほかに Database と Type で絞り込みができます。
Database では以下から選択できます。
| Database | 内容 |
|---|---|
| BioSample | サンプルの生物学的・実験的情報 |
| BioProject | 研究プロジェクト全体の情報 |
| SRA | 塩基配列データ(RNA-seqなどの生データ) |
| JGA | 日本のゲノムデータ(アクセス制限あり) |
| GEA | 遺伝子発現データ(マイクロアレイ等) |
| MetaboBank | 代謝物データ |
Type ではさらに細かく絞り込めます。
| Type | 内容 |
|---|---|
| sra-run | 実際のシーケンスラン(fastqファイルに対応) |
| sra-sample | サンプル情報 |
| sra-experiment | 実験情報 |
| sra-submission | 登録情報 |
| bioproject | プロジェクト情報 |
| sra-analysis | 解析情報 |
| jga-datasets / jga-study / jga-policy / jda-dac | JGA関連データ |
| gea | 遺伝子発現データ |
| metabobank | 代謝物データ |
RNA-seq解析の場合は Database: SRA、Type: sra-run または sra-experiment を選ぶと目的のデータに絞り込みやすくなります。
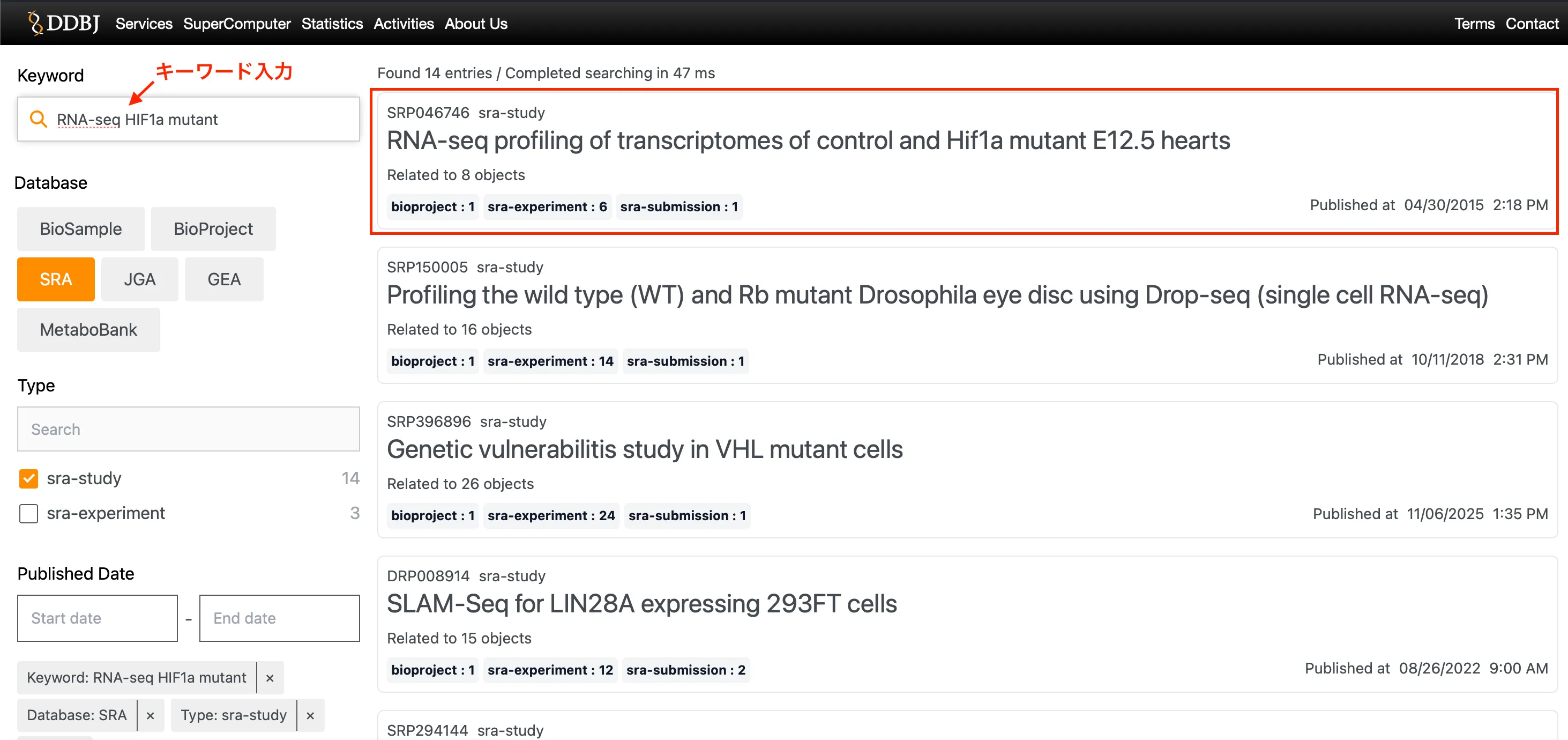
今回は、Database: SRA、Type: sra-studyを選択して出てくる「SRP046746」をクリックしてみましょう
2. AbstractとExperimentを確認
その実験の概要と各サンプル情報・データへのリンク(dbXrefs)が確認できます。
sra-experiment欄にそれぞれのサンプル情報へのリンクが記載されており、今回は6サンプル(SRX698161〜SRX698166)があります。
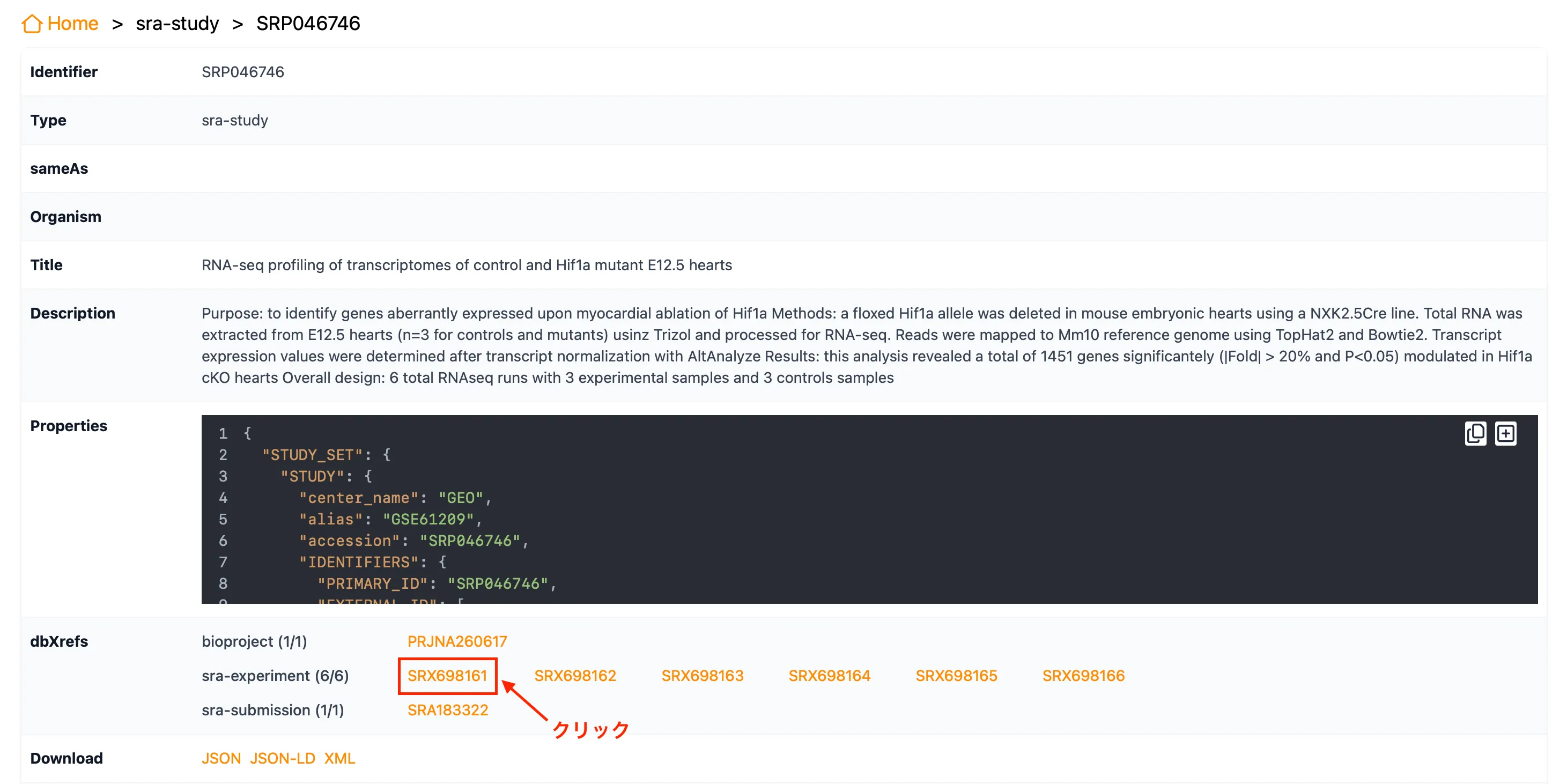
sra-experimentの一番左の「SRX698161」を開いてみましょう。
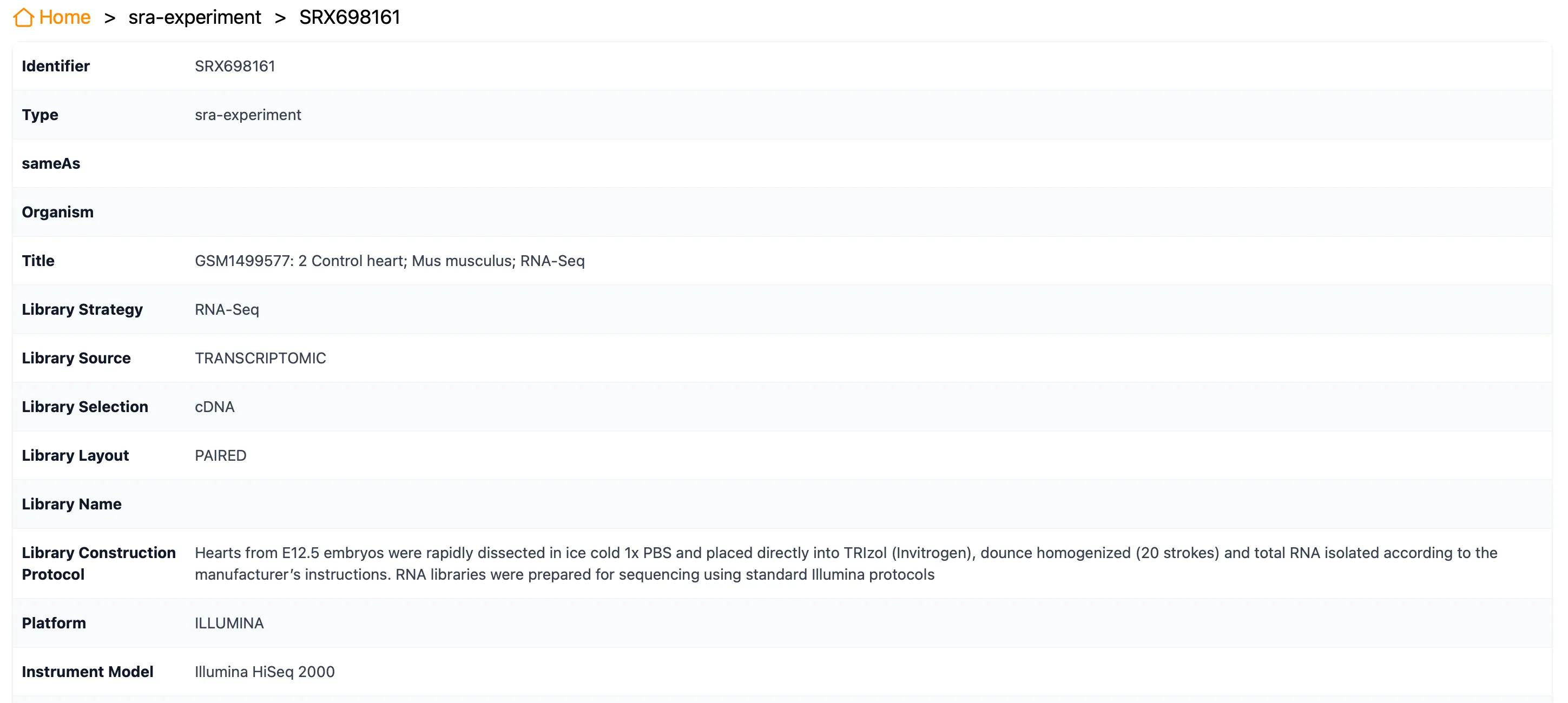
サンプル情報をよく確認しましょう。
| 確認したいこと | 見る場所 |
|---|---|
| 何処置サンプル?コントロール? | Title |
| RNA-seqかどうか | Strategy |
| 動物の種類 | Organism |
| シングルエンド?ペアエンド? | Layout |
3. FTPによるダウンロード
解析するデータも決まり、内容も確認しましたので、
実際にダウンロードしていきましょう!!
DDBJからはサーバーとのやりとりで使われるFTPを介してダウンロードできます。
FTPでは簡単にデータのやりとりができますが、速度が遅いことが多々あります。
気楽にすぐにダウンロードしたい方はFTPで十分だと思います。
ダウンロードはブラウザでクリックでもできますが、
折角ですのでターミナルを使いましょう。
FTPでのダウンロードにはwgetコマンドを使用します。
wgetのインストール
ターミナルを開いて出てくる$の後に、
以下のコマンドを打ってwgetをインストールします
$ brew install wget試しに、$の後ろに以下のコマンドを入力してヘルプが出れば、インストール完了です。
$ wget --help4. ダウンロードURLの取得
※必ずChromeで行ってください!!
先程のStudyのページからそれぞれのExperimentにある
fastqをクリックしましょう!!
すると、今回を例にとるとidの後ろに_1と_2のある.fastq.bz2ファイルがあるかと思います。
今回はペアエンドでのRNA-seqでしたので、_1と_2があります。
それぞれ、ダウンロードしましょう。
その前にフォルダ(ディレクトリ)の確認と移動は忘れずに!!
今回は、デスクトップにRNA-seqというフォルダを新たに作り、
そこに移動してそこにダウンロードしていきます。
$ pwd
/users/UserName/
$ cd Desktop
$ pwd
/users/UserName/Desktop
$ mkdir RNA-seq
$ cd RNA-seq
$ pwd
/users/UserName/Desktop/RNA-seqmkdir フォルダ名で新しいフォルダを作成できます。
RNA-seqというフォルダを作り、cd でそのフォルダに移動しました。
今回はここにfastqファイルをダウンロードしていきたいと思います。
ダウンロードする際はwget -c urlでダウンロードできます。
-cの前後は半角スペースです。
urlの部分には実際のFTPサーバーのURLを入れます。
wget -c ftp://ftp.ddbj.nig.ac.jp/ddbj_database/dra/fastq/SRA183/SRA183322/SRX698161/SRR1571967_1.fastq.bz2
wget -c ftp://ftp.ddbj.nig.ac.jp/ddbj_database/dra/fastq/SRA183/SRA183322/SRX698161/SRR1571967_2.fastq.bz2
wget -c ftp://ftp.ddbj.nig.ac.jp/ddbj_database/dra/fastq/SRA183/SRA183322/SRX698162/SRR1571968_1.fastq.bz2
wget -c ftp://ftp.ddbj.nig.ac.jp/ddbj_database/dra/fastq/SRA183/SRA183322/SRX698162/SRR1571968_2.fastq.bz2
wget -c ftp://ftp.ddbj.nig.ac.jp/ddbj_database/dra/fastq/SRA183/SRA183322/SRX698163/SRR1571969_1.fastq.bz2
wget -c ftp://ftp.ddbj.nig.ac.jp/ddbj_database/dra/fastq/SRA183/SRA183322/SRX698163/SRR1571969_2.fastq.bz2
wget -c ftp://ftp.ddbj.nig.ac.jp/ddbj_database/dra/fastq/SRA183/SRA183322/SRX698164/SRR1571970_1.fastq.bz2
wget -c ftp://ftp.ddbj.nig.ac.jp/ddbj_database/dra/fastq/SRA183/SRA183322/SRX698164/SRR1571970_2.fastq.bz2
wget -c ftp://ftp.ddbj.nig.ac.jp/ddbj_database/dra/fastq/SRA183/SRA183322/SRX698165/SRR1571971_1.fastq.bz2
wget -c ftp://ftp.ddbj.nig.ac.jp/ddbj_database/dra/fastq/SRA183/SRA183322/SRX698165/SRR1571971_2.fastq.bz2
wget -c ftp://ftp.ddbj.nig.ac.jp/ddbj_database/dra/fastq/SRA183/SRA183322/SRX698166/SRR1571972_1.fastq.bz2
wget -c ftp://ftp.ddbj.nig.ac.jp/ddbj_database/dra/fastq/SRA183/SRA183322/SRX698166/SRR1571972_2.fastq.bz2ファイルの解凍
bzip2ファイルの解答はbzip2 -d fileコマンドでできます。
-dの前後は半角スペースです。
fileのところには実際のファイル名が入ります。
bzip2 -d SRR1571967_1.fastq.bz2
bzip2 -d SRR1571967_2.fastq.bz2
bzip2 -d SRR1571968_1.fastq.bz2
bzip2 -d SRR1571968_2.fastq.bz2
bzip2 -d SRR1571969_1.fastq.bz2
bzip2 -d SRR1571969_2.fastq.bz2
bzip2 -d SRR1571970_1.fastq.bz2
bzip2 -d SRR1571970_2.fastq.bz2
bzip2 -d SRR1571971_1.fastq.bz2
bzip2 -d SRR1571971_2.fastq.bz2
bzip2 -d SRR1571972_1.fastq.bz2
bzip2 -d SRR1571972_2.fastq.bz2これで解析用ファイルの準備が完了しました。
次回からはいよいよHisat2によるマッピングを行っていきます。